
 English
English
Camila Larrosa
En artículos anteriores vimos qué es Machine Learning y comenzamos a profundizar en su primer subgrupo: el aprendizaje supervisado. A partir de esta publicación sobre el modelo de Naive Bayes, comenzamos a profundizar en cada técnica de esta categoría de aprendizaje automático.
El modelo de Naive Bayes (algorithm) es una clase especial de algoritmo de clasificación fuertemente basado en estadísticas. Es uno de los modelos más tradicionales, y aún muy utilizado, tanto en el ámbito académico como en el mercado.
Quien investiga, trabaja con o estudia Machine Learning debe entender su concepto y su funcionamiento. Al ser simple y fácil de entender, el modelo de Naive Bayes también es una buena forma de iniciarse en el área, para profundizar más adelante con soluciones más robustas.
¿Qué es el algoritmo Naive Bayes?
El algoritmo «Naive Bayes» es un clasificador probabilístico basado en el «Teorema de Bayes», el modelo fue creado por el matemático inglés, Thomas Bayes (1701 – 1761), para tratar de probar la existencia de Dios.
El término “naive” (ingenuo en español) se refiere a la forma en que el algoritmo analiza las características de una base de datos: ignora la correlación entre las variables características (features).
Es decir, si una pelota está etiquetada como «Pelota de tenis», y si también se describe como «Amarillo fluorescente» y «Diámetro pequeño», el algoritmo no tendrá en cuenta la correlación entre estos factores. Esto se debe a que trata a cada uno de manera independiente.

Además, este modelo también asume que todas las variables características son igualmente importantes para el resultado. Y por tanto, en escenarios donde esto no ocurre, Naive Bayes deja de ser la opción ideal.
Otra característica a tener en cuenta a la hora de elegir el algoritmo Naive Bayes es que su rendimiento también es considerablemente bueno con problemas de clasificación de múltiples clases.
Teorema de Bayes
Para comprender mejor el modelo, intentemos entender la idea detrás del Teorema de Bayes.
Este teorema se basa en calcular la probabilidad de que ocurra un cierto evento ‘A’, dado que ya ha ocurrido otro evento anterior ‘B’, lo que se denomina probabilidad condicional.
![]()
Dónde:
P(B|A) : Probabilidad de que B suceda, dado que A sucedió;
P(A) : Probabilidad de que ocurra A;
P(B) : Probabilidad de que ocurra B.
Veamos un ejemplo del Teorema de Bayes en el diagnóstico de enfermedades:
Sabiendo que:
- El resfriado provoca fiebre en el 50% de los casos;
- La probabilidad previa de que un paciente haya tenido un resfriado es 1/50000;
- La probabilidad previa de que un paciente haya tenido fiebre es 1/20
¿Cuál es la probabilidad de que un paciente diagnosticado con fiebre haya estado resfriado?
![]()
Es decir, la probabilidad de que el paciente haya estado resfriado previamente a la fiebre es del 0,02%.
¿Cómo funciona el algoritmo Naive Bayes?
Para entender cómo funciona el algoritmo de Naive Bayes, usemos un ejemplo más, volviendo al juego de tenis. De esta vez, debemos clasificar si los jugadores van a jugar o no con base en la previsión meteorológica.
Para ello, contamos con un conjunto de datos, con situaciones previas, mostrado en la Figura 2. Los datos contienen información sobre el tiempo (variable característica) y si hubo o no juego (variable objetivo).
Entonces, con esta información, responderemos ¿los jugadores jugarán al tenis cuando haga clima ensolarado?
También en la Figura 2 se listan los pasos que hay que realizar para utilizar el algoritmo Naive Bayes para solucionar problemas de clasificación como este.
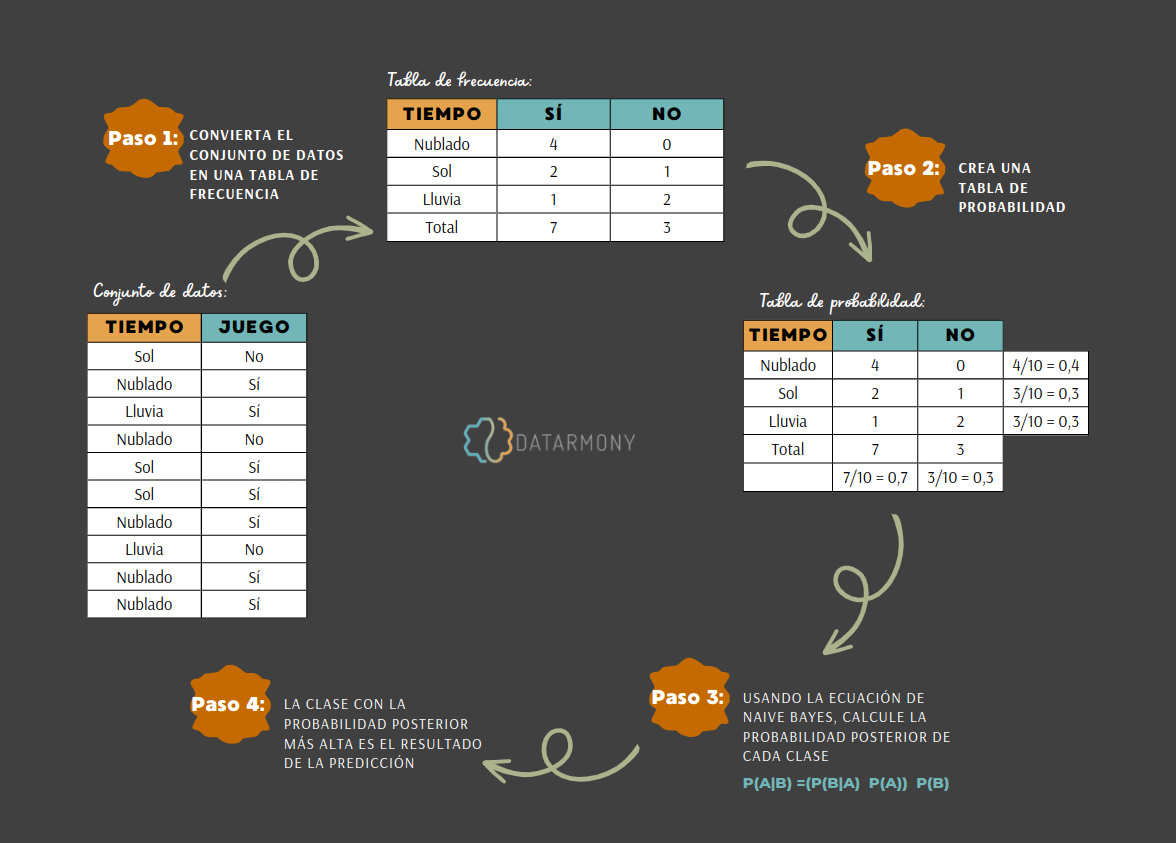
Aplicando el paso 3 para responder a la pregunta:
![]()
![]()
![]()
![]()
![]()
Es decir, con este resultado, sabemos que hay un 65 % de posibilidades de que los jugadores jueguen al tenis con tiempo soleado.
En problemas reales, Naive Bayes utiliza un método similar para predecir la probabilidad de diferentes clases en función de varios atributos, clasificando según la probabilidad de clase más alta.
¿Cuándo usar Naive Bayes?
Uno de los problemas más clásicos para ilustrar la utilidad de Naive Bayes es el clasificador de spam, donde el algoritmo analiza los correos electrónicos e intenta evaluar si son spam o no. Comenzar con esta aplicación, tiene una razón, ya que este es un algoritmo de uso frecuente para problemas de procesamiento de lenguaje natural.
Además, también es muy utilizado en el campo de la salud, como en diagnósticos médicos, determinando si el paciente tiene o no una enfermedad.
También es posible encontrar versiones del algoritmo en sistemas de recomendación, como el filtrado colaborativo y otros. En este caso, el objetivo de Naive Bayes es predecir si a un usuario le gustará o no un determinado recurso, y así sugerirle algo que pueda interesarle.
O sea, Naive Bayes es un algoritmo con aplicaciones muy versátiles, debiendo ser utilizado en los casos en que las variables sean condicionalmente independientes. También es un algoritmo que presenta un óptimo desempeño clasificando categorías muy bien separadas y para datos con dimensiones altas, donde la complejidad del modelo es menos importante.
Implementación de Naives Bayes en Python
De forma muy sucinta y precisa, su aplicación en Python consiste en importar la librería necesaria, entrenar el modelo y realizar predicciones:
# Importar la libreria
from sklearn.naive_bayes import GaussianNB
# Entrenamiento del algoritmo
modelo_nb = GaussianNB()
modelo_nb.fit(x_entrenamiento, y_entrenamiento)
# Predicciones de algoritmos para el conjunto de datos de prueba
prediccion = modelo_nb.predict(x_prueba)El resto del proceso, como el preprocesado de datos, la separación entre entrenamiento y prueba, y la evaluación del modelo, deben realizarse de forma análoga a otros modelos de Machine Learning.
En Datarmony trabajaremos muchos más posts como este, para que puedas conocer los conceptos y metodologías más interesantes.